AI-Powered Hybrid Search Engine
High-performance file search combining keyword and vector-based semantic retrieval, achieving 0.06s latency across 100k+ files.
 on [Unslpash](https://unsplash.com)](https://images.unsplash.com/photo-1461749280684-dccba630e2f6?q=80&w=1469&auto=format&fit=crop&ixlib=rb-4.1.0&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D)
Photo by Ilya Pavlov on Unslpash
Default OS search tools, such as Windows File Explorer or Nautilus, are slow and limited to filename matching. Windows File Explorer’s search can take several seconds even in small directories. Nautilus is extremly slow in large directories. Alternative third-party tools like Everything and FSearch improve performance significantly but can sacrifice content indexing, or in some cases raise security concerns. This gap inspired me to develop a search tool that is performant, with minimal search latency, and capable of search within file contents in addition to filenames.
This project provides a high-performance local file search engine that supports both keyword and semantic similarity retrieval, with efficient indexing, metadata filtering, and content previews, all accessible via a command-line, REST API, and Python Library interface. Throughout my work on this project, I prioitized engineering an efficient, privacy-preserving solution using proven information retrieval methods. Rather than inventing new Information retrieval techniques, the value of my work is in how these techniques are composed into a system that is fast, modular, and practical for real desktop use.
System Architecture
Responsiveness is the central design constraint of this project. The software architecture eliminates cold-start penalties with lazy-loading of models, no runtime dependency resolution, and low-latency search index persistence mechanisms. There are five core components of this project’s architecture:
System architecture: user queries enter via the CLI or Python API, route through a Flask REST API to the Indexing & Search Worker, which reads from LMDB, FAISS, and Gensim stores. A separate File System Crawler populates a Redis job queue (consumed by the worker) and a SQLite metadata database.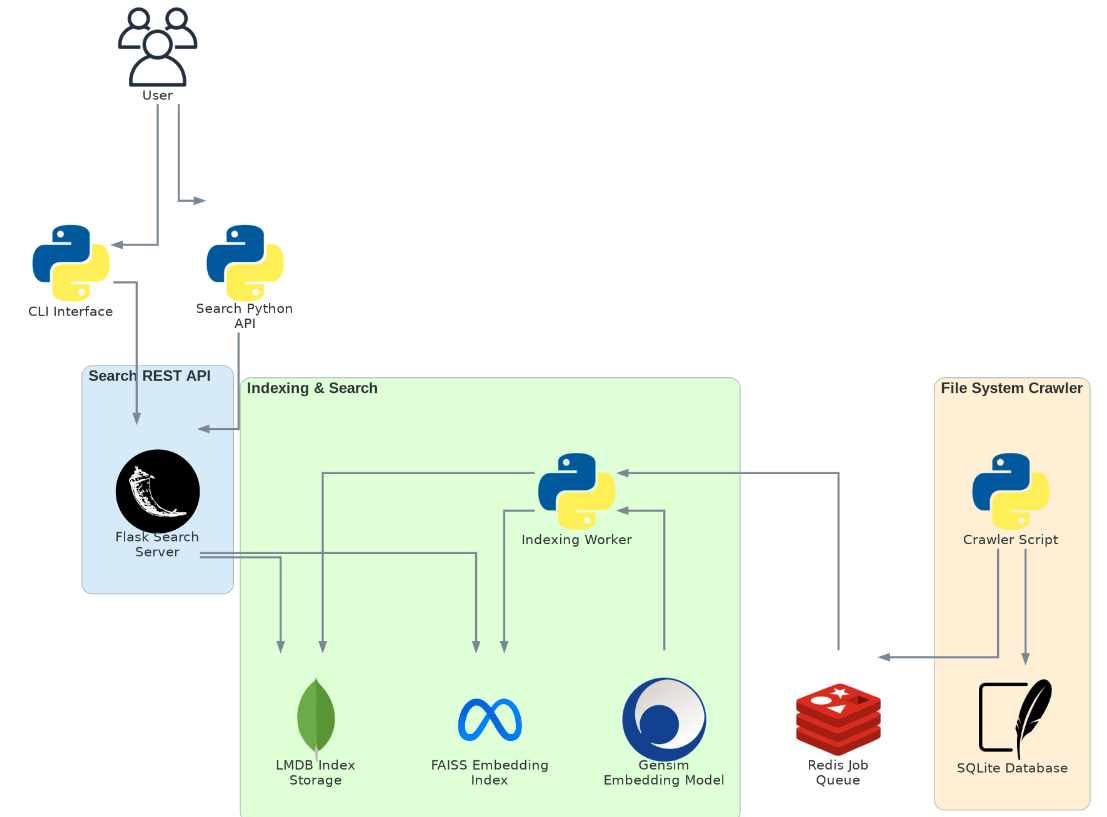
1. CLI Interface and Python Package API
The CLI and Python package API are the primary user-facing surfaces. The CLI enables terminal-based search and indexing; the Python package exposes a programmatic interface for integration into other workflows or applications. Both communicate with the backend exclusively through an internal REST API, keeping the user layer cleanly separated from backend layer.
2. Search REST API
A Flask-based web server acts as the gateway between users and the search engine. It handles HTTP requests from both the CLI and Python API, routing them to the appropriate backend services. Stateless, asynchronous communication with the Indexing and Search Worker enables scalable access patterns and keeps the UI layer decoupled from backend search logic. Results return in structured JSON, easily consumable by humans and programs alike.
3. Indexing and Search Worker
The Indexing and Search Worker is the central logic engine of the system. It processes file paths pushed to the Redis job queue by the file crawler, performing two tasks: (1) indexing file content for both bag-of-words (keyword-based) and semantic vector search, and (2) serving search queries against the FAISS and LMDB indexes. The Gensim-based embedding model (GloVe) loads into memory at startup of the worker processes, eliminating runtime loading latency. Model initialization and disk reads never occur during the query loop by design.
4. File System Crawler
Inspired by focused crawling and revisit strategies from web crawlers, the file crawler recursively traverses directories from a given root. It maintains a persistent record of visited files in SQLite, tracking paths, modification times, and internal flags, and pushes new or changed files to a Redis queue for indexing. The crawler runs independently of the indexer, enabling fully asynchronous, decoupled execution. A layered change-detection strategy using timestamps, file hashes, and listening to file system events minimizes redundant re-indexing while still catching moved or updated files.
5. Data Persistence
The project makes use of four distinct data storage solutions, each chosen due to distinct needs:
- SQLite: A lightweight, serverless, file-based relational storage for crawler metadata (visited paths, modification times, flags, hashes, etc.). Chosen over MySQL or PostgreSQL for its zero-setup embedded operation and fast local reads.
- Redis: An in-memory key-value store serving as a job queue between the crawler and indexer. Its native list/stream data structures, atomic operations, fault tolerance, and trivial setup beat IPC or file-based signaling for this use case.
- LMDB: A high-performance, ACID-compliant key-value store for the bag-of-words inverted index and FAISS vector ID mappings. Zero-copy reads and minimal dependencies make it ideal for low-latency, memory-efficient lookups, preferred over RocksDB and LevelDB.
- FAISS: A dense vector index for similarity semantic search over file content embeddings. Selected over Annoy and HNSWLib for its scalability, GPU support, and tight Python integration.
Search Quality
To ensure the search engine returns relevant results, the system was tested against the SARA dataset, a standard benchmark containing thousands of documents and human-rated relevance scores. This simulates a real-world scenario where a user asks a question and expects the most useful files to appear at the top of the list. I measured success using these metrics:
- Precision (P@10): Out of the first 10 results shown, how many were actually relevant? This measures the “noise” of the results. If a user has to scroll past irrelevant files to find what they need, the score drops.
- Mean Average Precision (MAP): This looks at the precision of the entire list of results, rather than the first 10 results. It rewards systems that put relevant documents early and irrelevant documents at the end. A high MAP score means that the search engine consistently understands the user’s intent across the whole evaluation set of queries.
- Mean Reciprocal Rank (MRR): How quickly does the first correct result appear? If the answer is in position #1, the score is perfect. If it’s buried at #10, the score plummets. This mimics the user experience of “finding it instantly.”
- Mean Normalized Discounted Cummulative Gain (mNDCG@10): This metric accounts for degrees of relevance. Sometimes a file isn’t a perfect match but is still “kind of” useful (e.g., a draft version of a document). This score rewards the engine for ranking the “perfect” match at #1, the “good” match at #2, and the “okay” match at #3, rather than mixing them up. It ensures the most useful content is at the top of results, rather than relying on binary relevance labels to determine ranking effectiveness.
- Query Speed: How long does the user wait? In a desktop tool, anything over 1 second feels sluggish; under 0.1 seconds feels instantaneous.
| Method | P@10 | MAP | MRR | mNDCG@10 | Avg. Query Time (s) |
|---|---|---|---|---|---|
| Hybrid | 0.1220 | 0.2429 | 0.4454 | 0.1398 | 0.0539 |
| BM25Okapi | 0.2273 | 0.3210 | 0.5066 | 0.2702 | 0.0485 |
| GloVe Semantic | 0.0827 | 0.1355 | 0.2280 | 0.0837 | 0.0077 |
| SARA BM25 Benchmark | 0.1893 | — | — | 0.2009 | — |
The BM25Okapi implementation exceeds the SARA benchmark on both reported metrics (P@10 and mNDCG@10), confirming that the keyword retrieval pipeline is competitive with established baselines on real-world relevance tasks. The semantic model trades ranking precision for speed (0.0077s average query time) and captures relevance that purely lexical methods miss, which is the entire point of offering it as a complementary mode. The hybrid approach blends both, providing a practical middle ground where contextual matching matters alongside exact term overlap. Across all modes, queries return in well under a second, compared to the multiple seconds typical of Windows File Explorer or Nautilus, even across 100k+ file indices. The system delivers the speed of dedicated third-party tools like Everything while supporting content-aware and semantically meaningful retrieval that those tools cannot.
Design Decisions & Extension Points
Every engineering decision throughout this project involved tradeoffs. While work on this project is currently on pause, there are several natural extensions when I return to this project:
- Sequential vs. parallel hybrid execution. The hybrid semantic and keyword search currently runs BM25 and semantic retrieval sequentially before interleaving results. Running these in parallel would reduce hybrid query latency, but the current sequential approach keeps the system simple and already achieves ~0.05s response timesm, fast enough that the added complexity of concurrent execution wasn’t justified for the initial implementation but may be justified in future work.
- Fixed-weight score blending vs. learned ranking. The hybrid mode uses fixed interleaving of BM25 and semantic results. A learning-to-rank approach or dynamic score weighting could produce more contextually optimized rankings, but would introduce a training pipeline and labeled data requirements that add significant complexity for the marginal gains given the current retrieval quality. I am still curious how much learning-to-rank would improve the ranking results of this system, were I to tackle this challenge with more resources than I had in my initial work on this project.
- Static embeddings vs. contextual models. The GloVe embeddings used by this project provide fast, deterministic vector representations. Contextual models like SBERT or DistilBERT would capture richer word-in-context semantics, but at substantially higher computational cost and latency, trading away one of the system’s core advantages. The current embedding choice was made balancing between semantic capability and the sub-second responsiveness goal, but further efforts could be justified to testing where exactly these computation and latency costs exceed the value more complicated embeddings provide. It is also worth invesitigating whether cloud-based LLMs could be effective, or if the latency introduced by network communication would be too much.